
Why human brain only needs a small amount of data (or is it?)
- Neville Huang

- Oct 9, 2019
- 8 min read

One of the most commonly mentioned questions about the differences between AI and real intelligence is the amount of data needed to achieve the same performance. Artificial intelligence, as we know, is extremely data-hungry. According to one estimation based on the trend in 2016, for a supervised deep learning algorithm, it will require 5,000 samples for each category in order to reach a satisfying accuracy. As to equaling or even exceeding human level, the amount of samples required for each category expands to more than 10,000,000 (喻儼 et al., 2017)! Human beings, on the other hand, are able to quickly pick up new things from an extremely small dataset. Normally, glancing once at a certain example (e.g., a Persian cat lying on the ground) of a category will be sufficient for us to accurately recognize another instance belonging to the same category under a completely different scenario (e.g., another Persian cat jumping between sofas).
In this article, we’re going to discuss the possible reasons behind the small data requirement of human brain, and hopefully it can shed some light on how to reduce the amount of data needed for training an AI model.
The power of characteristic-based recognition
Speaking of visual recognition, there are two completely different strategies. The first one is based on analyzing the whole pattern of a target (i.e., pattern-based), while the second focuses merely on its characteristic features (i.e., characteristic-based). To understand their difference, see the following example:

Most people have no problem identifying the cartoon face in Figure 1 as Jack Sparrow from Pirates of the Caribbean played by Johnny Depp. However, on closer inspection, you’ll notice that the overall physical pattern of the cartoon face is actually very different from the real one (see Figure 2). If our brain relied solely on analyzing overall pattern to distinguish faces, we should not make the conclusion that the two faces in Figure 1 belong to the same character. In other words, to this particular recognition task, the characteristic features (e.g., the red headscarf on the characters’ head, the shape of their mustaches and goatees, their smoky eyes and the “X” mark on their right cheek, etc.) play a more dominant role than overall pattern in this particular recognition task (to be fair, our brain depends on both characteristic- and pattern-based mechanisms for recognition under different situations; we’ll discuss this in another article).

It’s worth mention that the characteristic-based mechanism takes part in more basic recognition tasks as well, like identifying a geometry shape or a specific pattern; the only different is that the characteristic features used in such cases are far simpler than those in identifying Jack Sparrow’s face. Figure 3 (a) shows an example of how we remember a complicated pattern, and Figure 3 (b) enumerates the possible visual features that our visual system utilizes to define an object in sight. Note that the features demonstrated in Figure 3 (b) are arguably the most basic features used by our visual system, meaning that all objects visually presented can be defined by a specific combination of these features.
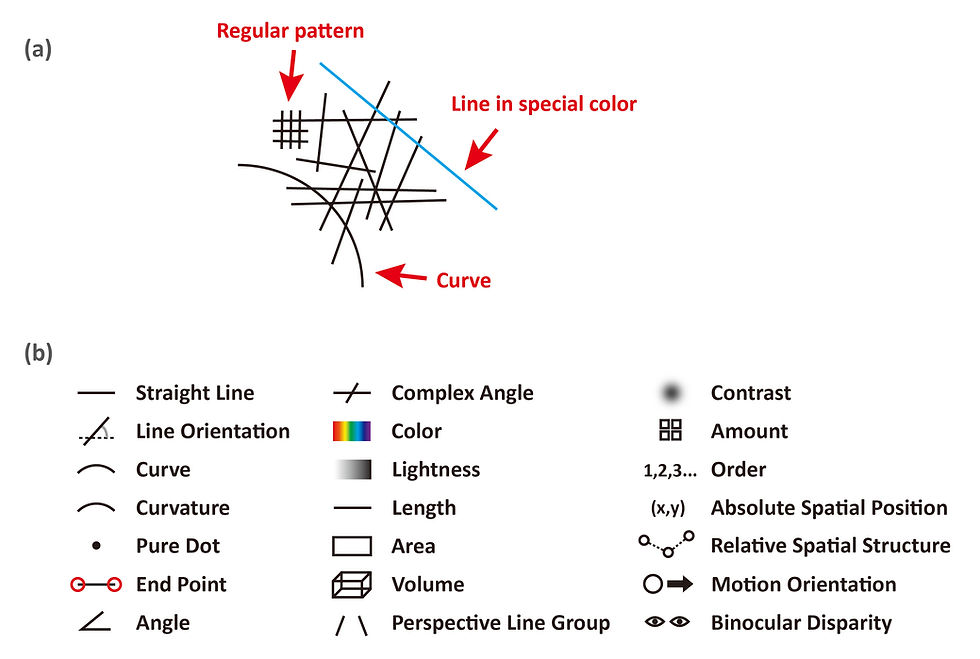
From Figure 3 (a) we can get a clear idea about what are “characteristic features”, that is, the features significantly different from its “surroundings (i.e., the rest of the figure or other similar figures)”. In our example, at least three such features can be detected. The first one is a regular pattern on the upper left as opposed to other randomly distributed lines; the second is a curve at the bottom as opposed to the straight lines elsewhere, and the third is a blue line that stands out from all the black lines.
So what are the advantages of characteristic-based recognition? First, it depends significantly less on a particular instance (i.e., it prevents overfitting and increases flexibility). As we can see from Jack Sparrow example, as long as the key features are present, the identities of two figures will be perceived as the same even if they may be very distinct in their overall structures. Second, we can teach one a concept by simply describing the key features of that concept without showing him or her any actual instances. For example, instead of demonstrating a person a series of real squares, we can make him or her understand what is a square by telling them “it’s a shape with four edges of equal length and four right angles”, and this is especially useful when we attempt to explain abstract knowledge to others since such knowledge usually lacks actual instances.
The second advantage said is also critical for reducing the data required for learning a new thing because it allows us to catch the key features of a concept directly through simple instruction instead of slowly extracting such features from a body of samples (P.S., the later is what an artificial neural network does).
So, it seems that we’ve found the answer to the question that why human brains require only a small amount of data: our brain is capable of quickly capturing the “characteristic features” of a new object or concept and therefore skirt the lengthy process of learning the overall patterns and details by going through zillion of examples (P.S., note that the “characteristic features” may mean different things for different recognition tasks. For instance, in the task of identifying a person, the features we resort to are things such as a mustache or an ornament. But in the task of recognizing basic pattern or geometrical shapes, the features used are far simpler. However, all of these characteristic features are derived from the most basic visual features as shown in Figure 3 (b), in which all visual objects can eventually be perceived as a combination of these features).
“But wait! How do our brains know which features are characteristic in the first place?” You may want to ask, and that’s a very good question. As a matter of fact, we must point out that a well-trained and well-designed artificial neural network (ANN) can also pick up a new instance (e.g., a new face) just by looking at a picture of that instance once! Therefore, we’d like to propose the following possibility: Our brain actually requires just as much data as an ANN, and the only reason that it seems less data-hungry is because it has already be trained for more than a hundred million years or so!
Evolution = The hugest model training session for brain
A baby's brain isn’t born as a blank piece of paper. Instead, it is endowed with many circuits and networks that are functional immediately after birth. Granted, many of them need environmental stimuli and further training to release their full power, but these circuits are genuinely innate and is capable of determining the utmost of our abilities (e.g., you can never teach a monkey to speak English since they lack the cerebral network responsible for language processing).
The reason these circuits exist and work so efficient lies in the fact that our cerebrum has been shaped by evolution for countless years. During the process, our genetic information, which serves as the source code of a neural network, will be examined by our environment, and those successful ones will be preserved while the unsuccessful wiped out. Then, The code retained will be slightly rewritten and passed down to the next generation, and the whole selecting process repeats so that better neural networks can be created. As you can see, everything is just like how we train an ANN except for two things. First, the modification of the networks in evolution is realized by sexual reproduction and genetic mutation, not backward propagation. And second, the improvement of the performance is not shown on the original network; instead, it is demonstrated on a new one originating from the previous generation through reproduction.
Through evolution, our brain has accumulated experiences from the largest “dataset (i.e., the stimuli coming from the surroundings)” that no ANN has undergone before, and perhaps it’s an important reason that why our wetware is more versatile and flexible than any artificial neural network we have today!
The power of general intelligence
While there are people believes that human brain can function properly with only a little data, some goes even further to claim that we can think or create based on absolutely no data at all! And they often support their allegation with something like the following examples: (1) an artist can draw a picture that haven’t been seen before, and (2) a scientist can create an unprecedented theory that looks totally unintuitive (one famous case is Albert Einstein’s special relativity).
So, are we really capable of performing tasks based on zero data? Unfortunately, I believe it’s yet another illusion created by the fact that our cerebrum is a generally intelligent system, meaning that it can process multiple sorts of sensory input (e.g., visual, auditory, olfactory, etc.) / information (e.g., images, words, math, etc.) and is multifunctional.
The special thing about our brain as a generally intelligent system is that it’s a combination of numerous distinct sub-networks, each has its own expertise and experiences (e.g., we have cerebral areas for processing language, faces, episodic memories, etc.), and they can communicate with each other in many circumstances to produce an outcome that can be considered novel.
Below, we listed three potential ways of how the interaction between networks with different functions can lead to the production of a creative or innovative result:
When a sub-network has no sufficient experience for completing a task, it can borrow experiences from another sub-network. This usually happens in art and design, where an artist or designer borrow inspiration from another area.

The knowledge between two (or more) sub-networks can be blended together to create a new outcome.

Our brain can extract some general rules or knowledge from the experiences held by different sub-networks, and then applying the rules or knowledge to solve the problem in another area. For instance, “mathematics” is a field people invented according to the quantitative relationships we summarize from daily experiences, and people can use such knowledge to resolve a broad range of problems.
Note that from the discussion above, we should learn a critical difference between an artificial neural network and a real cerebrum when they are trained with an inadequate amount of data. To an ANN, such situation will almost inevitably result in poor performance, and the quickest way to fix this will be to train your model with more data. To a real brain, however, a poorly trained sub-network may obtain support from other sub-network(s) that has received better training, making outputting satisfactory consequences with very little information possible, and as a result giving us a misapprehension that human brain requires almost no data to operate as expected.
Conclusions
Creating a superintelligent machine with a tiny dataset is a holy grail in the field of AI, and some seem to put their hope on studying our brain. Unfortunately, we do not believe it’s a valid strategy! A real cerebrum should be just as data-hungry as an artificial neural network, and the reason that it doesn’t look that way is because it has already been trained for a very long time.
In that case, does it mean that we can never create a neural network model that request less data? Well, we believe the answer to the question is a “no”. However, it’ll require a researcher, corporation or institute to be generous enough to share their well trained models with the general public, so that instead of training a naïve network from scratch, other researchers can make improvement on the basis of a trained model, and we should expect that the amount of data required in such situation will be significantly lesser than starting from ground zero.
Merging networks designed for different functions to create a semi-AGI (artificial general intelligence) may also be an option, but it’ll take more than simply linking two individual ANNs together. In our opinion, the key will be to train a high-level neural network that is capable of seeing the commonalities between two (or more) things (e.g., what do “a car” and “an airplane” have in common? Answer: They both help us moving from one location to another). With that being said, this is merely our speculation; to confirm it, more research will have to be done.
Footnote: Neurozo Innovation shares viewpoints, knowledge and strategies to help you succeed in your quest. If you have any question for us, please feel free to leave a comment below, or e-mail us at: neville@neurozo-innovation.com. For more articles like this, please join our free membership. Thank you very much for your time, and we wish you a wonderful day!



Comments